论文笔记
PINN
论文发布时间比较早,项目仓库的源代码还是用的tensorflow1,虽然也找到了tensorflow2的项目,但为了复现结果,仍使用tf1。
原项目仓库没有requirements.txt,观察一些代码用法,推测可用的版本环境:
python=3.7 tensorflow=1.15 numpy=1.21.5 scipy=1.7.3
按照原文的顺序,先验证Data-driven solutions of partial differential equations,就是通过学习数据的深层表征,获得一定知识,来预测该环境下的任意解。
分两部分,连续时间模型和离散时间模型。
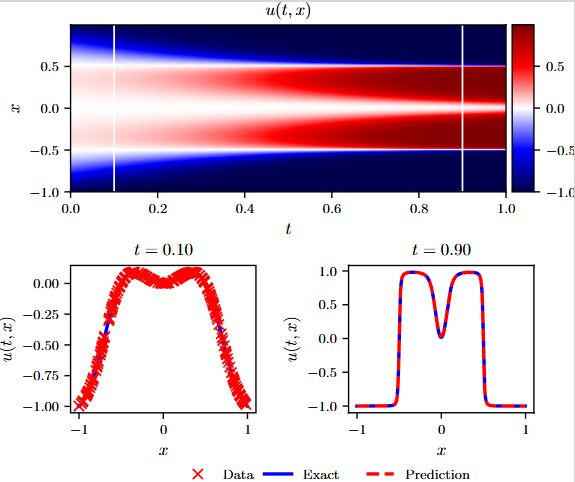
正向求解连续时间模型:Schrodinger equation
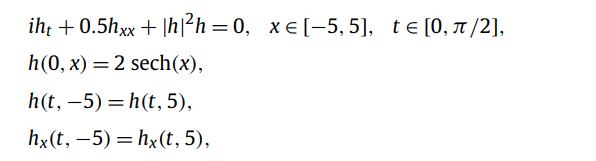
非线性薛定谔方程,h是波函数,有非线性项,是一个复值函数。解决此类问题需要网络有处理虚部和实部耦合的能力,还要能学习到非线性项带来的复杂反馈机制。该方程组的边界条件比较特殊,属于周期性边界条件(PBC)。
用于训练的数据有三类:
一是初始数据点,用于学习初始条件。
二是边界条件配置点,用于学习边界条件。
三是随机采样配置点,用于学习整体规律和PDE。
三种点的损失函数不一样,直接相加在一起。
问题:针对不同的PDE,面对不同的边界复杂度和初始点复杂度,三种采样点的配比变化会如何影响模型性能?如何量化条件的复杂度以分配最合适的训练预算?(原文是50:50:20000)
 对于这种复数值函数,其实是分成双通道,实数部和虚数部分开训练的,然后加总的。
对于这种复数值函数,其实是分成双通道,实数部和虚数部分开训练的,然后加总的。
训练10000次后基本处于震荡状态,稳定性略微提升。
It: 11390, Loss: 8.021e-04, Time: 3.45
It: 11400, Loss: 6.592e-04, Time: 3.55
It: 11410, Loss: 6.030e-04, Time: 3.51
It: 47780, Loss: 7.230e-04, Time: 3.73
It: 47790, Loss: 3.342e-03, Time: 3.65
It: 47800, Loss: 8.952e-04, Time: 3.55
It: 47810, Loss: 4.907e-04, Time: 3.49
It: 47820, Loss: 9.819e-04, Time: 3.53
Loss: 1.5793171e-06
Training time: 18643.0046
Error u: 1.457998e-03
Error v: 1.877740e-03
Error h: 1.085605e-03
本地运行了三次基本都这个范围。
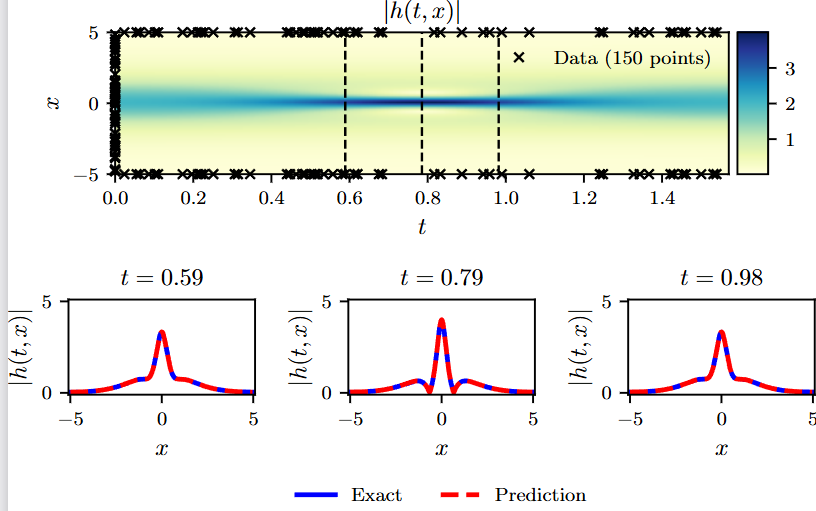 和论文相比1.97e−03相比稍好。
和论文相比1.97e−03相比稍好。
正向求解离散时间模型:Allen-Cahn 方程
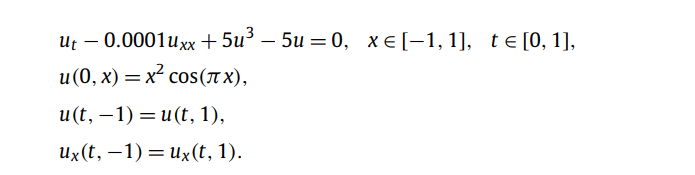
主要描述相分离之类的现象,有双势陷,可以看成系统的吸引子,自动让系统回到能量最低的状态。里面的uxx项是拉普拉斯算子,用来平滑尖峰的,描述扩散效应。
初始条件比较复杂,既有相位振荡,又有幅值变化,从低维度来看,整个空间的规律极度不会很规整,如果像连续时间模型那样,直接拉丁超立方采样整个空间,效果可能会比较差,因为普通的神经网络学习不到这么深层次的规律。如果用神经算子的方法,从更高的维度(用核函数)去计算,可能会更好一点。
而且这个方程的uxx项的系数非常小,让方程整体的刚性更强(这个要看雅可比矩阵的最大最小特征值的比值),用之前的方法或普通显式的RK方法,求解过程会不稳定、振荡、难收敛,论文的模型使用隐式Gauss-Legendre方法求解,具有A-稳定性。
边界条件依旧是周期性的。
离散时间模型相较于连续时间模型性能更加优越,首先我觉得主要是损失函数的性质起了作用。连续模型的正则项,强行让结果符合偏微分方程,但本质上网络中并没有提供更高效的算子,有过拟合的风险,学不到更细节的。而离散时间模型,换了一种先验知识,模型提供了IRK的系数,让预测结果天然符合微分方程的基本数学性质,我觉得这种形式能让微分方程的知识更为平滑地反映到网络参数中。
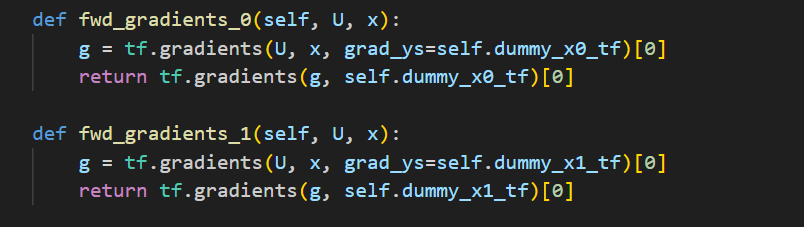
代码里面还用了一个Forward-mode AD Trick,关于方向导数的技巧。因为存在拉普拉斯算子,所以要求二阶导,本质上就是要存储整个雅可比矩阵,会OOM。所以使用了dummy技巧,在计算图中插入了向量点乘,直接计算Jv,然后对v求导就提取出来了J。
本地复现
Loss: 0.0049196924
Loss: 0.0049196924
Loss: 0.0049196924
Loss: 0.0049196924
Error: 4.877824e-03
 结果与原文为 6.99e-03相比稍差。
结果与原文为 6.99e-03相比稍差。
反向求参连续时间模型:Navier–Stokes equation
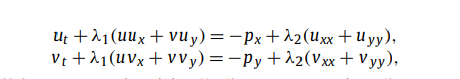
主要用于描述流体力学的方程,二维的,速度分成了xy两个分量,复杂度主要来自于主要uux+vuy这种非线性的对流项,由于是自相乘、高度耦合的,所以要求网络对一阶导数的捕捉必须极其精准,否则之后误差会迅速放大或不稳定振荡。
Uxx+uyy项目描述了粘性。
方程规定了Ux + Vy = 0,就是说散度等于0。
神经网络是双输出的。
一个输出一个隐式的流函数,描述Ux + Vy = 0
另一个输出动量函数p。
通过两个输出函数的自动微分,得到损失函数需要的其他项。
 可以看到把lambda两个参数都作为神经网络的参数来对待,持续更新。
可以看到把lambda两个参数都作为神经网络的参数来对待,持续更新。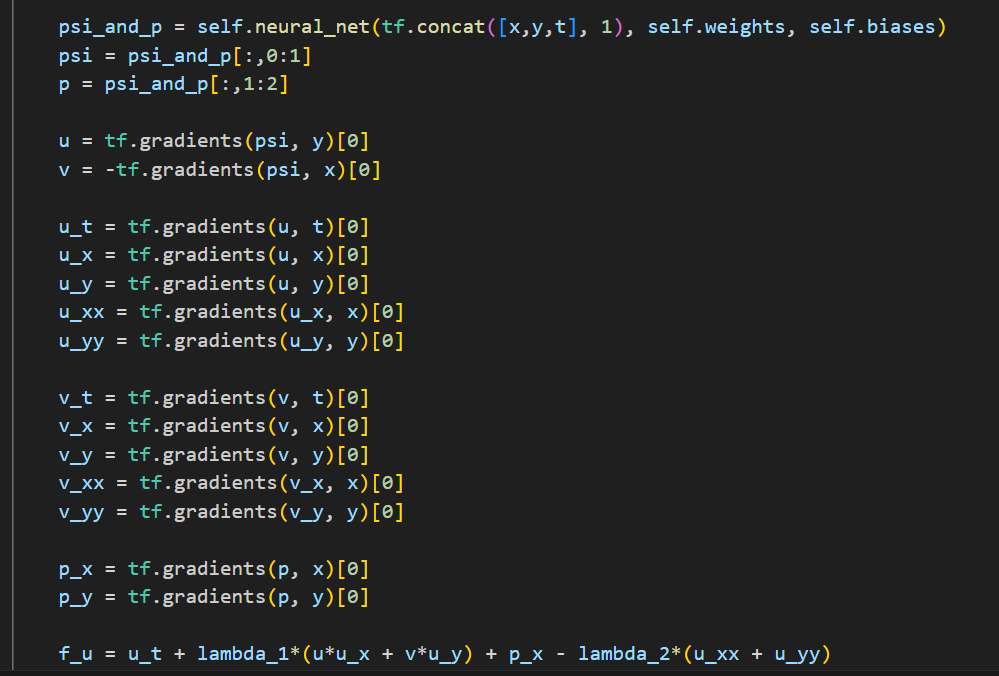
该方程的计算量和数据量过大,要跑很久,本地没有成功复现。
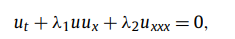
反向求参离散时间模型:KDV
比较典型的含有高阶导数的PDE,描述了长波运动。
Uux表示非线性对流,正反馈,U越大的地方,反馈越强。
Uxxx属于色散项,会导致相位的移动,不同频率波的速度会不一样。
 相较于AC方程,该方程由于含高阶导数,规律更为复杂,使用的是两时刻(过去和未来)的RK方法,以更好地学习内在知识。
相较于AC方程,该方程由于含高阶导数,规律更为复杂,使用的是两时刻(过去和未来)的RK方法,以更好地学习内在知识。
相应的损失函数也发生了变化。
 两时刻的误差都要计算。但底层用的是同一套参数。
两时刻的误差都要计算。但底层用的是同一套参数。
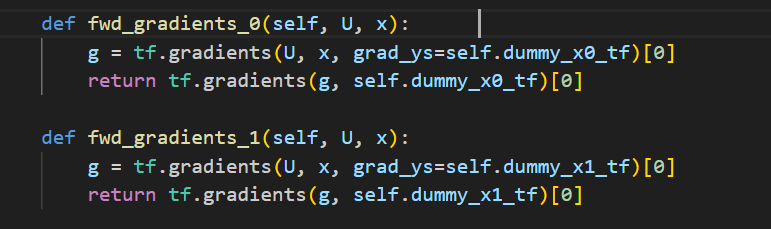 因为存在高阶导数,也使用了前向梯度的技巧。
因为存在高阶导数,也使用了前向梯度的技巧。
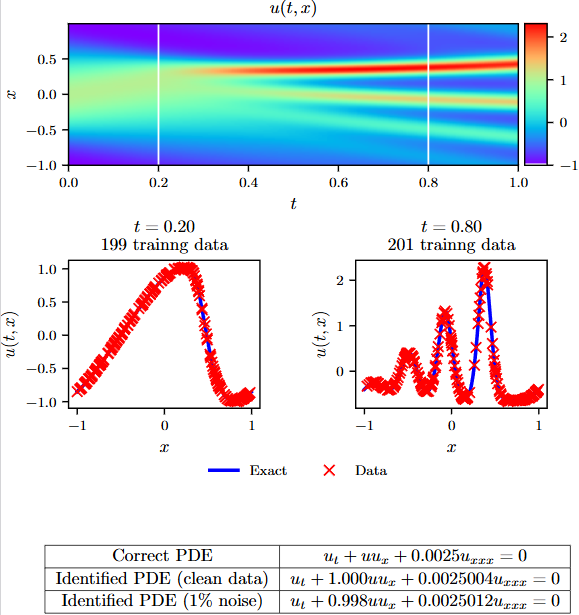 本地复现(不加噪版本)
本地复现(不加噪版本)
Loss: 0.892427
Loss: 0.892427
Loss: 0.892427
Loss: 0.892427
Error lambda_1: 0.155616%
Error lambda_2: 4.6492%
与原论文的0.17%和4.67%相比,基本一致。
本地复现的结果与原论文的结果有一定差异,证明该方法的稳定性还是有所欠缺。作者在原论文里面也说可以采用贝叶斯优化等系统方法对结构进行精细调优,评估预测结果准确性的方法可能是采用贝叶斯方法后检测后验分布的方差。但原文并没有实现。可以认为现有网络结构存在一定的不稳定性。
GNOT
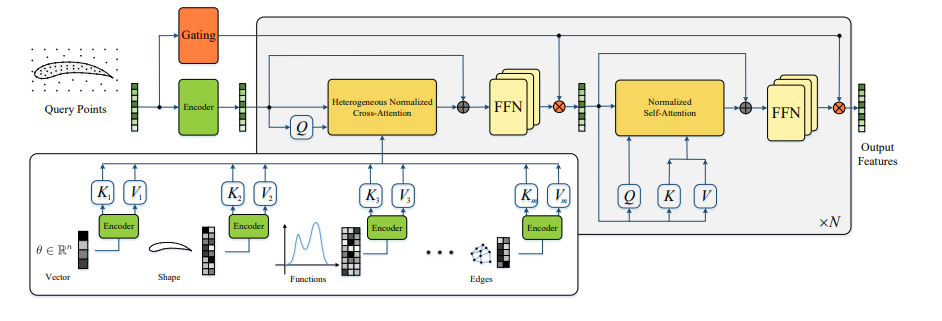
与PINN不同,GNOT不使用正则化技巧,也就是说不是从损失函数上约束网络去学习PDE中的潜在知识;它是使用神经网络,去学习PDE方程组中的知识,将神经网络拟合成符合数学物理公式的高效求解算子,属于神经算子的一种范式。
GNOT对普通的神经算子做了很多优化工作,解决了三类问题:irregular mesh,multiple inputs, and multi-scale problem。
这三类问题的我的理解如下:
①不规则网格:现实的数据都是分布在曲面等不规则平面上的,此时不适宜使用PINN中拉丁超立方采样得到的数据,也就说数据没有固定的结构和间隔,需要处理这种irregular mesh的情况。
②多类别输入:我的理解就是不同维度、不同种类的先验知识,前提是可量化,单纯的PDE方程组就不好直接嵌入。但边界点、固定的物理参数等就可以嵌入,以更好优化模型性能。
③多尺度问题:即耦合的多物理场,在近场和远场,对应的PDE方程差异较大,难度不一,需要学习的是不同的
这三种问题,作者分别用了三种对应的方法来解决。
①对于不规则网格,作者先通过MLP将所有配置点都变换为了查询嵌入X(query embedding)
② 对于多类别输入,作者也是通过MLP将对应的不同类型的输入,变换为了条件嵌入Y,分为K矩阵和V矩阵(就是注意力里面的key 和 value,后面异构注意力层直接用作为交叉注意力来使用)。
对于多类别输入,作者也是通过MLP将对应的不同类型的输入,变换为了条件嵌入Y,分为K矩阵和V矩阵(就是注意力里面的key 和 value,后面异构注意力层直接用作为交叉注意力来使用)。
③对于多尺度问题,作者使用了MOE的门控机制,将配置点的坐标作为输入,得到了不同专家子网络的加权评分,根据评分对不同子网络的输出求个平均,得到最终输出。
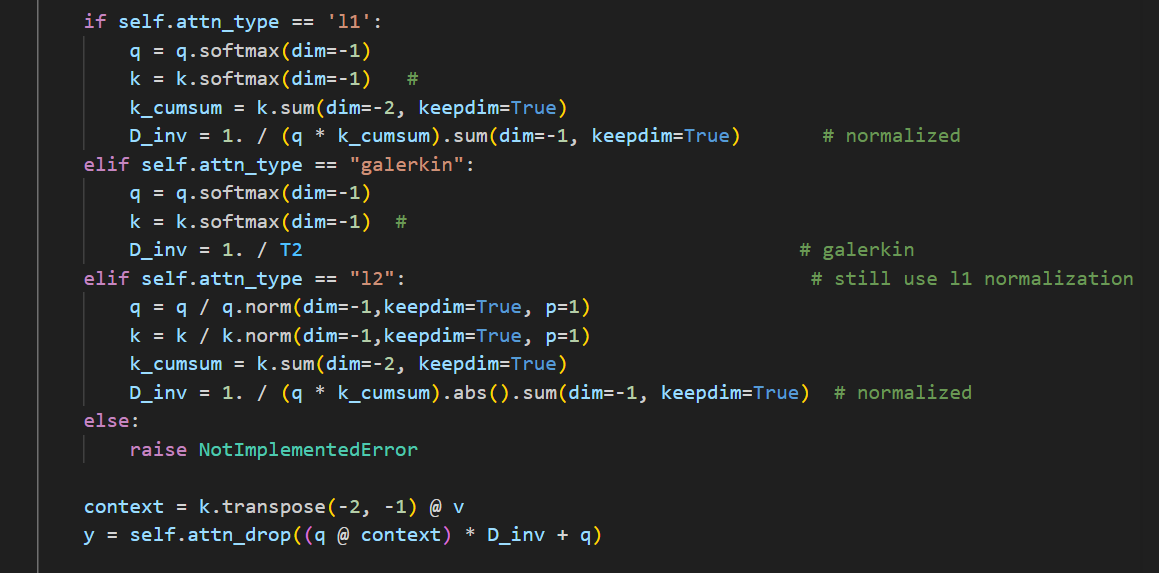
 除此之外,作者也对注意力块的运算效率做了优化。舍去了softmax,先对Q和K矩阵归一化,使用线性注意力,提高了计算效率。
除此之外,作者也对注意力块的运算效率做了优化。舍去了softmax,先对Q和K矩阵归一化,使用线性注意力,提高了计算效率。
个人理解:本质上transformer的单头自注意力块本身就属于非线性积分核算子的一种特殊形式。也就是说QKsoftmax矩阵可以一种特殊的可学习的核函数。
从这种意义上来讲,我认为,GNOT或者神经算子框架,在解决数学物理问题方面是天然更有优势的。神经算子框架提供的积分算子以及核函数,是更高级的运算,能够将数据变换到更高的维度,从更高的维度学习耦合物理场的深层次知识。而且对于各类先验知识,只要可转换为数据,都可以进行嵌入,兼容性更好一些。
而传统的PINN,依旧依赖普通的全连接层和激活函数,全连接提供加性和乘性运算,以及激活函数提供的非线性能力,我觉得不足将数据的特征提升到一个足够高的维度,以学习深层知识。它起作用依赖正则化技巧,我觉得较为生硬,面对复杂规则容易过拟合(离散时间模型会稍微好一些)。但是PINN的优势我觉得在于是对于先验知识,可以通过一种可控制的程度进行嵌入和影响神经网络(比如加入权重参数),配合神经算子也许能够提高训练效率。
本地复现了NS2d实验
Training takes 12127.52312040329 seconds.
Best model’s validation metric in this run: {‘metric’: array([0.01327785, 0.03011134, 0.01433284], dtype=float32)}
与原论文的结果6.73e-3,1.55e-2,7.41e-3有一定差异。
FNO
这篇文章的核心思想是直接在傅里叶空间中对积分核进行参数化,从而使网络更加高效、更有表达力。
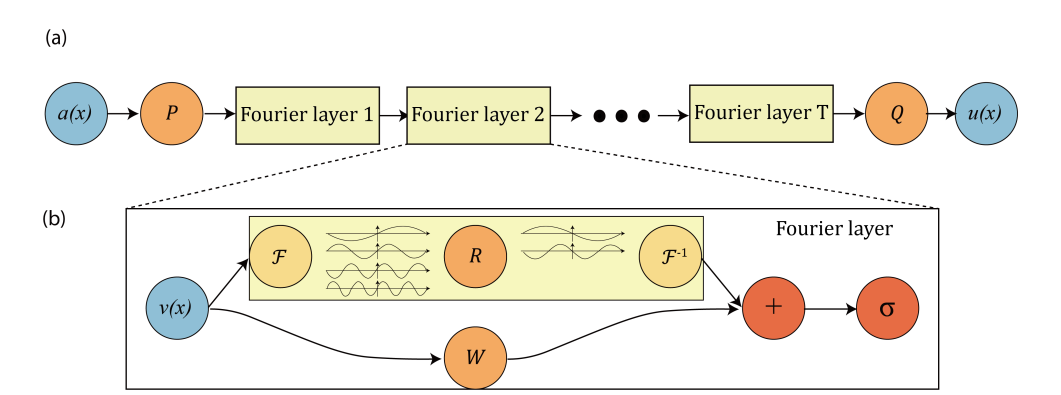 整个模型由三阶段构成。(以一阶傅里叶算子为例)
整个模型由三阶段构成。(以一阶傅里叶算子为例)
①Lifting
即将原始输入映射到高维空间,对它的特征进行初步提取。用的是简单的全连接层。
②Fourier Layer Process
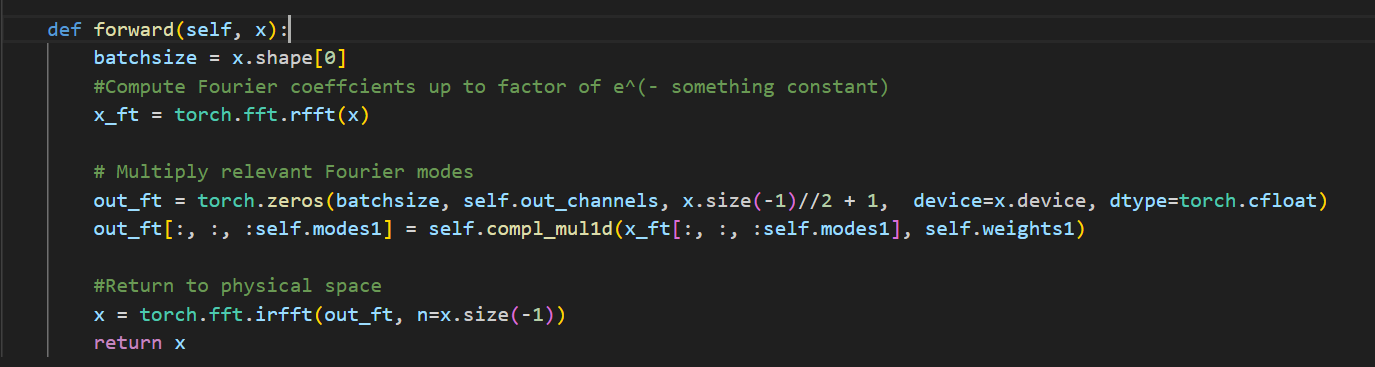 对Lifting处理后的高维表示进行傅里叶变换,然后在频率中进行线性变换处理,并且以最大模态数Kmax为限制,过滤高频部分,再将结果拟傅里叶变换回空间域,
对Lifting处理后的高维表示进行傅里叶变换,然后在频率中进行线性变换处理,并且以最大模态数Kmax为限制,过滤高频部分,再将结果拟傅里叶变换回空间域,
这样的过程原文中进行了四次。
这里有个类似skip connect的处理。高维表示会分流,分别通过普通的全连接层和傅里叶算子的处理,相加起来再经过激活函数。
这里的本质要训练的也还是核函数和全连接层。
Geo-FNO
 将经过四次傅里叶算子处理的高维表示映射回目标的输出维度,得到最终的结果,即PDE的解。
将经过四次傅里叶算子处理的高维表示映射回目标的输出维度,得到最终的结果,即PDE的解。
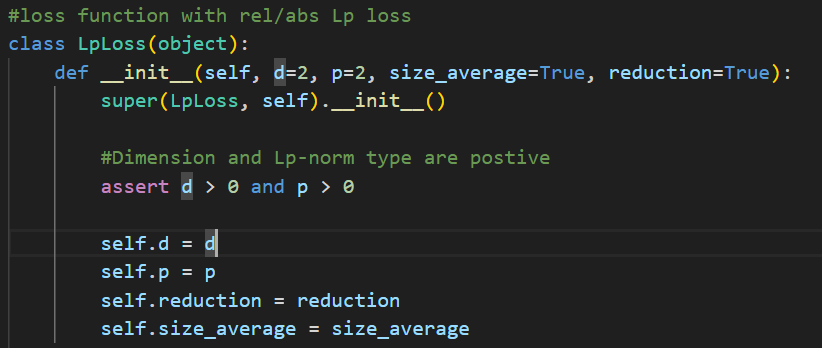 这里使用的是LpLoss,不是传统的MSE,因为样本本身具有多尺度特征,量级可能不一样,用相对误差更公平。
这里使用的是LpLoss,不是传统的MSE,因为样本本身具有多尺度特征,量级可能不一样,用相对误差更公平。
另外,输入维度不同的时候,频率截断的操作会发送变化,比如2D的傅里叶频谱呈现出边角共振结构,为了滤除高频噪声,它不仅要截取左上角的低频角块,还需要截取左下角的低频共轭区域。
我对于傅里叶算子的理解:在PDE问题的数据的schema中,各个数据存在一种深层次的耦合关系,判断某一点的变化需要对全域的其他点对其的影响进行积分,感觉上类似于格林函数。**在neural operator里面,有数学上格林函数类似的概念,就是核函数,本质上是判断两个数据的耦合关系,从而衡量数据的深层知识背后隐藏的一种信息流动。**但是在显式空间内进行积分核操作的复杂为O(N2),而如果转化到频域中,就可以变为点乘操作,虽然转换空间有了额外的开销,但整体开销是更小的(前提是利用FFT)。傅里叶算子假设核函数是卷积核,即数据背后对应的物理定律具有平移对称性,这样一来,不仅可以在频域用点乘代表时域的积分,还可以利用快速傅里叶变换。
但是我认为这种“平移对称性”也是一种强先验,可能不适用很多物理情景,没有单纯的GNO去学习核函数有泛化性。
(注:卷积核让原积分核可以转换到频域并用点乘处理。涉及泛函知识。卷积算子和移位算子是对易的,其特征函数都为复指数函数,与傅里叶变换的基函数天然契合。卷积算子处理特定频率的复指数函数时,只会缩放其强度倍数,而不会产生其他频率分量,所以是正交的,可以转换为独立点乘。)
用原论文数据集复现了一维傅里叶算子(Burgers1d)的实验,
不同分辨率的结果如下:
256: 0.08914431100711226
2048:0.08943957068026066
4096:0.08879734247922898
8192:0.08840862581506372
其结果与原文结果的趋势一致。
Geo-FNO
主要还是解决了FNO的网格输入问题。先通过学习把输入映射到均匀网格空间,再去运用FNO。这样一来输入格式具有了很强的灵活性,不均匀的点云、网格、参数都可以变为输入了。
其实感觉和GNOT的思路有点类似,面对多尺度的、不规则的多源数据,都先过一层神经网络,映射到特征空间,转化成规则的向量或张量。起到了特征学习的作用,也为后续的网络提供了规整的输入。
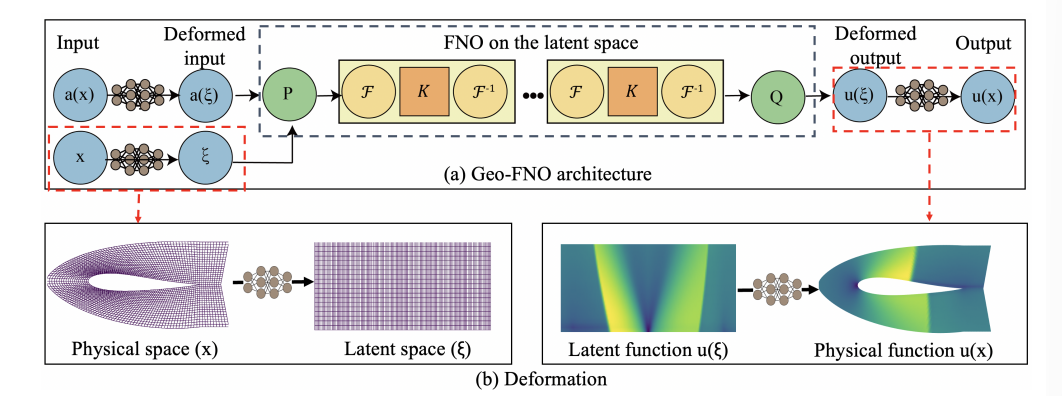 在网络结构上,与FNO相比,显著变换就是在输入后和输出前加了一层Deformation Net,用来把不规则的物理空间和均匀的潜空间进行一个对换。隐层主要还是正常的FNO算子。
在网络结构上,与FNO相比,显著变换就是在输入后和输出前加了一层Deformation Net,用来把不规则的物理空间和均匀的潜空间进行一个对换。隐层主要还是正常的FNO算子。
关于Deformation,涉及了一些拓扑学的知识。首先自适应网格和规则网格应该微分同胚,这规定了映射函数的性质。物理空间到训练空间,实际上是一种谱变换,我们需要训练空间的基是标准的傅里叶基,也就是说真实物理域的谱空间中的基函数如果用傅里叶形式表示,不再是简单的复指数形式,而是一种耦合的复指数形式,需要乘一个雅可比行列式的导数才能恢复正交属性。
另外Deformantion这一层还做了很多特征增强的处理。增加了角度和径向距离作为原始输入,和坐标一起,进行了一个类似位置编码的操作,通过正余弦序列,编码了细粒度的位置信息(一定程度上可以缓解Spectral Bias)。最后原始输入经过全连接层扩展到width的维度,和经过正余弦编码的另外两个特征一起,构成了3*width的特征输入。这里还有code表示全局的几何信息。
 我对于Geo-FNO的理解:主要还是解决了FFT无法处理不规则网格输入的问题。主要的启发还是相关的谱理论。不同谱空间的基函数的形式不一样,这导致了谱空间的性质也不一样。在谱空间进行计算,有时可以带来计算上的便利,比如将复杂的积分问题转化为点乘问题,但前提是数据要符合对应基函数的性质,比如傅里叶要求周期性,这样点乘的时候才能保证基函数的正交性。可能面对不同数学物理问题时,可以根据先验知识,选择合适的谱空间进行运算。
我对于Geo-FNO的理解:主要还是解决了FFT无法处理不规则网格输入的问题。主要的启发还是相关的谱理论。不同谱空间的基函数的形式不一样,这导致了谱空间的性质也不一样。在谱空间进行计算,有时可以带来计算上的便利,比如将复杂的积分问题转化为点乘问题,但前提是数据要符合对应基函数的性质,比如傅里叶要求周期性,这样点乘的时候才能保证基函数的正交性。可能面对不同数学物理问题时,可以根据先验知识,选择合适的谱空间进行运算。
疑问:以傅里叶谱空间为桥梁,通过神经网络学习到合适的映射函数,将其他数据先转换到傅里叶谱空间再进行快速计算;与通过神经网络直接学习合适的基函数,将原数据变换到最合适的谱空间进行计算,两者是否存在性质上的差异。
对论文的Hyper-elastic problem的实验进行了复现。
相对误差0.02463984742760658
论文的测试集相对误差为0.0229,基本一致。
所得图像也基本一致。
PINO
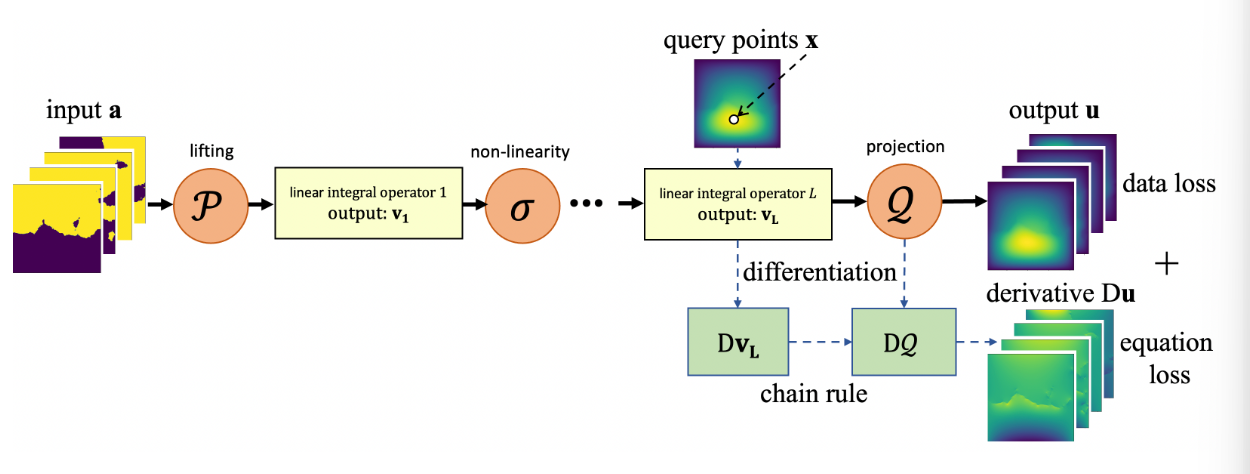 如其名,就是PINN和NO的结合,使用了神经算子,同时损失函数使用了PDE作为正则项。
如其名,就是PINN和NO的结合,使用了神经算子,同时损失函数使用了PDE作为正则项。
主要由两个阶段组成。
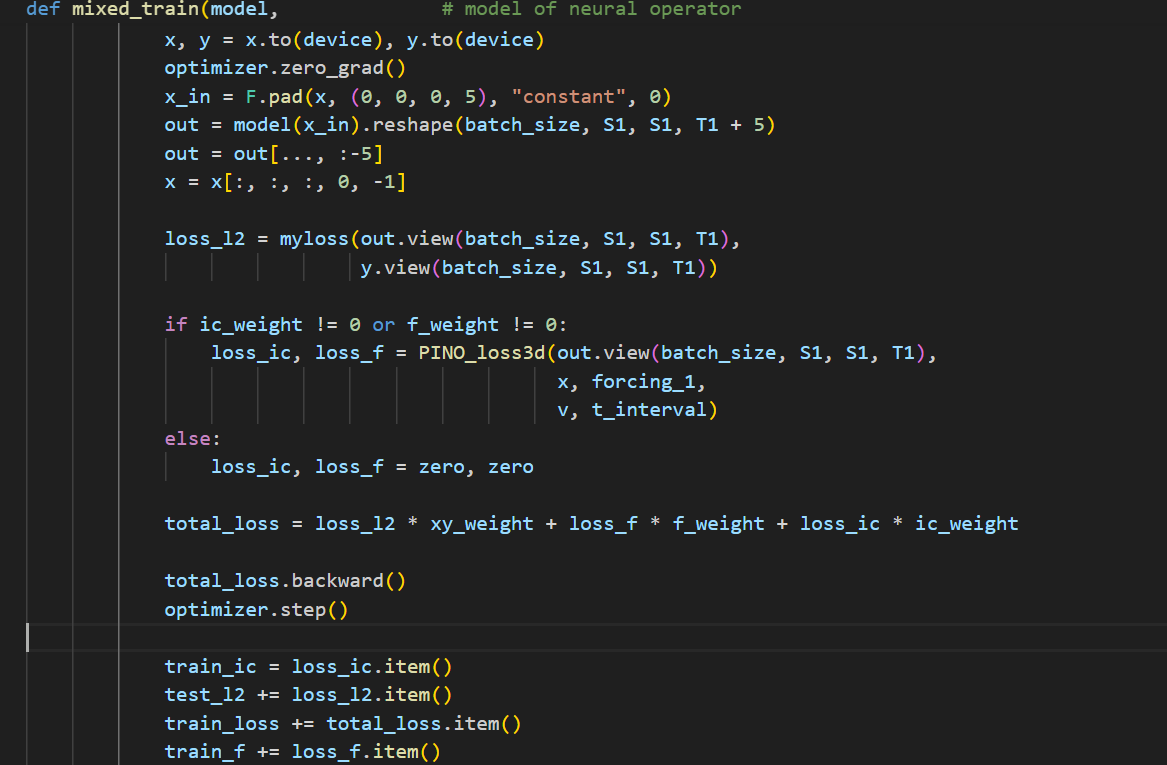 ①算子学习。这部分训练的损失函数可以由两部分构成,一部分是低分辨率数据对应的预测损失,另一部分就是检验是否符合物理现象先验的PDE损失。但是通过抽取初始条件和系数条件,可以生成无限的实例和数据,不需要知道正确答案,只需要保留PDE损失对其进行训练就可以了,即去掉数据结果的预测损失。
①算子学习。这部分训练的损失函数可以由两部分构成,一部分是低分辨率数据对应的预测损失,另一部分就是检验是否符合物理现象先验的PDE损失。但是通过抽取初始条件和系数条件,可以生成无限的实例和数据,不需要知道正确答案,只需要保留PDE损失对其进行训练就可以了,即去掉数据结果的预测损失。
②实例微调。这一阶段,将第一阶段学习到的神经算子作为ansatz(试探函数),由他生成假设解。训练过程类似于PINN,不过这里不是使用神经网络而是神经算子。这里使用了一个锚点损失,计算的是微调前的算子的预测结果和微调后的算子的预测结果之间的误差,用以防止算子过拟合。而主要的精度提高,还是依靠PDE损失,让算子学习深层的物理规律。

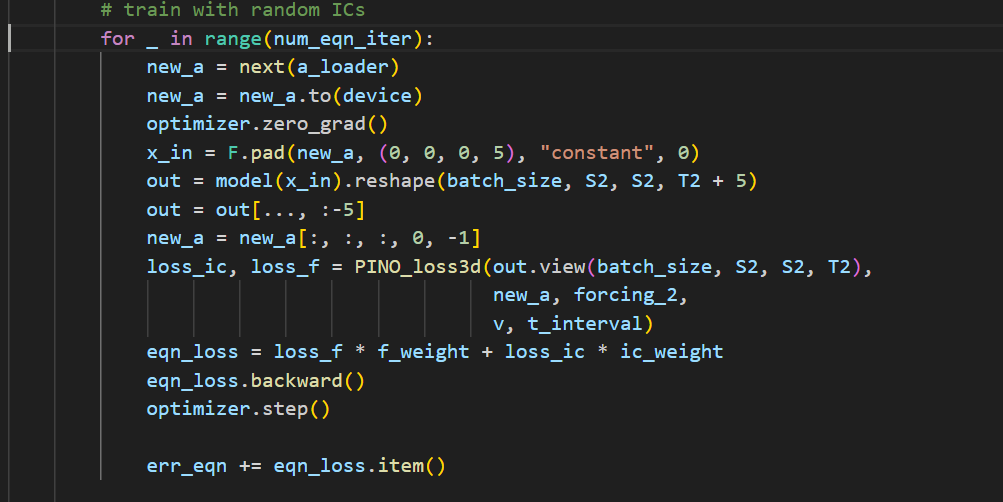 有一个修饰器技巧,可以让边界条件变为硬约束,越靠近边界,结果肯定越来越趋近0,不将边界条件作为另外的正则项加入,避免了训练过程在边界的振荡。
有一个修饰器技巧,可以让边界条件变为硬约束,越靠近边界,结果肯定越来越趋近0,不将边界条件作为另外的正则项加入,避免了训练过程在边界的振荡。
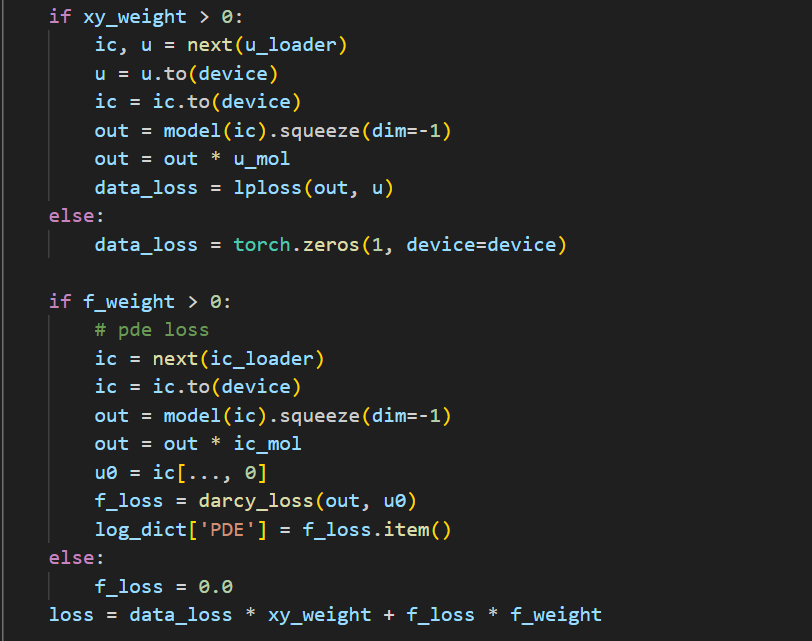 是通过调整不同正则项的权重来控制训练阶段的。
是通过调整不同正则项的权重来控制训练阶段的。
复现了改论文的burgers实验。
实验结果:==Averaged relative L2 error mean: 0.00625483624113258, std error: 0.0002751613152924056==
==Averaged equation error mean: 2.1402136196684298e-05, std error: 2.1236889629770403e-06==
差异较大,可能是训练时候的epoch设置不同,但原论文里面似乎没有明确说明。
数据集交叉验证
涉及的物理方程实验及其数据集:
- FNO:Burgers1d,Darcy2d,NS2d
- Geo-FNO:Elasticity,Airfoil Flows,Plasticity,NS,Euler’s Equations,Advection
- GNOT:自主数据集接口(可普适不规则网格、多输入、多尺度),如下表格:
| 数据集 | 不规则网格 | 多输入 | 多尺度 |
|---|---|---|---|
| Darcy2d / NS2d | ✓ | - | - |
| Elasticity | ✓ | - | - |
| NS2d-c | ✓ | - | ✓ |
| NACA | ✓ | - | ✓ |
| Inductor2d | ✓ | - | ✓ |
| Heat | ✓ | ✓ | ✓ |
| Heatsink | ✓ | ✓ | ✓ |
- PINN:Schrödinger,Allen-Cahn,Navier-Stokes,KdV
1、用GNOT测试FNO、Geo-FNO的数据集
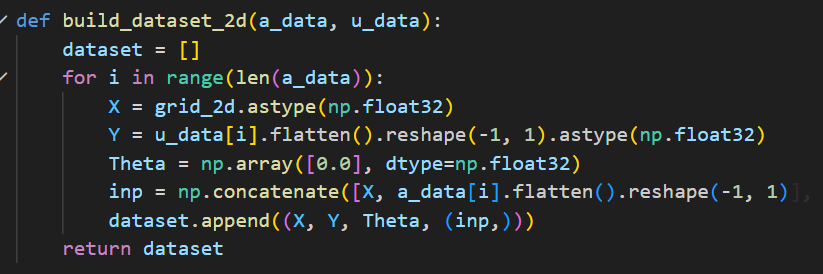 GNOT强行规定了所有PDE数据集都必须统一抽象为[X, Y, Theta, Inputs_funcs]这种图、点云格式。FNO和Geo-FNO的数据集无法直接使用,需要进行转换。
GNOT强行规定了所有PDE数据集都必须统一抽象为[X, Y, Theta, Inputs_funcs]这种图、点云格式。FNO和Geo-FNO的数据集无法直接使用,需要进行转换。
其中目标点坐标特征为X,每个点应该输出的目标真实值为Y。Theta是全局环境参数,此处设为0。
我们这里使用三个实验进行测试,Burgers1d、Darcy2d、Airfoil2D
三者的训练参数都如下:
Epochs:500 batch size:10 lr:0.001
①Burgers 1d
Training takes 3277.6463923454285 seconds.
Best model’s validation metric in this run: {‘metric’: 0.014637558}
使用的与FNO相同的数据集burgers_data_R10.mat。
得到的结果比较好,与原论文的结果相近,但是并没有发挥GNOT根本的优势。
GNOT可以接收非网格数据、多源输入,对于不同参数的物理方程也有较强的学习能力。因为这个数据集的参数是固定的,这里只是用[0,0]去填充了Theta,表示没有全局参数变化。
②Darcy2d
Best model’s validation metric in this run: {‘metric’: 0.034926638}
原论文结果0.01左右,比FNO的结果稍差。
可以理解,因为测试时并没有加入其他特征项来充分利用GNOT的网络架构优势。原论文用GNO作为baseline,结果在0.05左右,和GNOT的结果比较相近。这和之前提到的注意力机制本质上是GNO的变体这个理论相契合,二者的机制相近,结果应该类似。
③Airfoil Flows
metric in this run: {‘metric’: 0.0052650934}
与原论文的56X51网格上训练并预测221X51网格的结果0.0428相比,有较大提升。可能是由于Airfoil这种非均匀网格,与GNOT结构更加适配,多尺度输入下,GNOT能通过MOE机制更好地学习近场和远场不同的特征。
2、用PINN测试FNO、Geo-FNO的数据集
这一部分实际上不太兼容。PINN只能用于单个实例的学习,本质上是神经网络学习,不是算子学习,FNO和Geo-FNO的数据集基本都是混合实例,初始条件不同,或者参数不同,难以转换到PINN的框架上进行训练。
3、用FNO、GNOT测试PINN的数据集
PINN的数据集都是固定实例的,即初始条件、模型参数是一定的。
好在PINN的数据集大都是网格特征,所以可以在FNO上进行训练。
但是问题在于PINN训练是逐点输入,FNO期望的数据格式是[样本数,空间网格数,通道数],直接把一个网格当成一个样本输入,PINN的参数是一定的,不能作为额外的通道特征,需要进行数据转换处理。PINN的数据集的第二维度都是时间切片,所以可以把时间的切片作为通道数。
GNOT的处理类似于1中所提。
用GNOT框架测试薛定谔方程,结果为0.36176252,与原论文结果1.97e-03相比,差异比较大,而且为相对L2范数,这代表该结果基本不可信。
用GNOT框架测试了AC方程,结果为0.039075077
用FNO框架测试了AC方程,结果为0.0411667645
与PINN原论文的6.99e-03相比,显著更大,也基本不可信。
PINN数据集数据量相对少,且参数固定,可能在其他GNOT和FNO这类框架的测试中,反而没有学习到足量知识,整体的框架的泛化性没有得到体现,反而限制了性能。
数据转换的过程可能也存在问题。
模型对比和总结
①PINN,将物理公式、边界条件等先验知识作为正则项,利用较简单的神经网络进行学习。面对固定的、不那么复杂的数学物理实例,效率比较高,需要的数据量也没有很大,接收非网格化的输入,比较灵活。但是受限于正则化技巧和网络结构,泛化性比较差,本质上不是学习数学物理过程的根本规律,而是在拟合单个情景下的演化趋势。而且面对存在高阶导、耦合非线性项的复杂PDE,该方法依赖的自动微分工具需要较大的内存去存储链式关系,由于表达能力受限,精度和稳定性都会下降。
②FNO,属于神经算子框架,用神经网络去逼近算子的性质,核心是傅里叶变化。不同于PINN,它不加入额外的正则项,拜托了确定PDE和边界条件的性质,仅通过数据误差来训练,依靠的是积分核来学习全局的深层耦合关系,学习的是数学物理过程的深层规律,泛化性较强,学习到的是无限维映射,而且具备零样本超分辨率的能力。FNO属于神经算子家族,特点在于利用卷积核,将积分转换为了频域的点乘,而且使用快速傅里叶变化,提高了整体的运算效率,本质上是利用了谱变换。缺点是输入必须是规则网格,否则谱变换后的傅里叶基不再正交,求解精度和稳定性会大幅下降。
③Geo-FNO,整体架构类似于FNO,为了处理非均匀的网格,扩展FNO层的应用场景,引入了Deformation,将各类不标准的物理空间映射到规则的计算空间,其中映射算子需要自行学习。个人理解本质上还是谱变换,只不过是多了一个学习基函数的步骤,能够让原空间耦合的傅里叶基(或者说原空间本来就不是傅里叶基,只是我们用傅里叶基去表示或拟合),能够在计算空间重新实现正交性,进而使用FFT和频域乘积加速运算。
④GNOT,依旧属于神经算子框架,不同于FNO和Geo-FNO,它一种是特殊的图神经算子,核函数不再限制为卷积核,而是通过注意力的形式来表示和学习。GNOT的最大优势在于对于输入的宽容度极高,可以单点输入,不仅接收非网格化输入和多尺度输入,而且接收边界条件、参数、分布情况等等非结构化的输入,核心技巧在于所有输入都会先通过MLP提取为规整的高维特征,作为后续注意力机制中的QKV,并通过异构注意力层来进行统一融合。为了减少运算压力,使用了线性注意力机制,取消了softmax。还使用了Moe机制,依靠数据点的特征来对多个FFN的结果进行加权融合,增强了模型的泛化性和稳定性。
PINN和NO的结合运用
最显而易见的方式就是把两种方法直接相加,利用神经算子架构的同时引入PINN的正则项技巧。这种思想在PINO中得到了实践。PINO的特点在于两阶段训练,PDE损失贯穿其中,数据损失虽然只在第一阶段使用,但是让网络学习到了整体的大概知识。第二阶段实例微调提高分辨率同时引入锚点损失,能保证网络不偏离大方向,同时更加贴合物理实际。
我的个人理解是,在PINN此类框架中,PDE、边界条件等,象征了人类对物理客观世界的高度规律总结,属于非常强而且正确的先验知识。通过神经算子框架,神经网络具备了更高维度的运算能力,即使没有任何先验,也能够从数据中学习得到潜层知识,但如果有先验知识的融入,可以大大加快网络的学习过程,以及保证它学习结果的正确性和稳定性。所以我认为核心问题在于,怎样把非结构化的先验知识,特别是函数方程、边界条件等无法通过单一数据点来表示的无限维特征,平滑地嵌入神经算子框架中。我目前有以下两个不同的想法(但尚未经过实验或文献论证,需要后续进一步研究):
①任何PDE或者解函数,应该都可以用基函数表达,所以通过PINN框架直接学习基函数。具体而言,将x输入N个互不干扰的自注意力模块构成的短小子网,N代表子网的数量,作为超参,每一个子网都代表一个基函数。同时x也要经过一个FFN系数网络。子网输出的值,和系数网络输出对应的权重,二者加权求和作为最终的值。而损失函数主要包括PDE损失和数据损失。由于基函数正交,只需要对不同的子网络进行求导再相加即可得到最终结果的导数。除了这两个损失,每经过200个样本计算一次不同子网输出的内积的绝对值,最小化这个内积,目标是让不同子网实现正则化。
这样可以接收各类输入,包括不规则网格,并且可以根据复杂程度自适应调整子网数量,来适应不同的场景。
②输入是规则化的数学语言,比如将PDE和边界条件用latex公式表示,通过一个大语言模型,输出一个权重向量,代表不同种类的神经算子的权重,原始输入通过各类神经算子后的输出以这个权重求和,得到最终解。大语言模型需要提前训练,这个过程应该仅训练神经算子。
泛化性很强,针对不同的物理数学情景,不用再硬编码。
前置大语言模型的训练是一个问题,稳定性存在问题。