众所周知,React 和 Vue 3 是目前前端开发中最主流的两种框架,本科生在各类课程里面(软工、数据库等)多多少少接触到了这两种框架。由于课程需求,大家可能更多地关注两种框架的语言特性、语法糖等具体编码层面的内容,而忽视了“框架”层面的内容。因为react和vue3不是作为一门“语言“而存在的,而是一套”框架“,拥有不同的历史背景、生态系统、商业环境,这些不同就造就了它们设计哲学和理念的差异,而正是在不同的哲学和理念的差异下,对于响应式系统、路由管理、开发者体验等重要议题,它们有不同的实现方式,从而发展出了不同的底层技术路线。而本文想探讨的,正是从”框架“层面的设计哲学和理念出发,去对比react和vue3在技术原理上的差异,以及背后折射出来的设计理念的差异。
1. 核心范式:Pure JS 和 Enhanced HTML
一切差异的源头,始于二者对“如何描述 UI”这一根本问题的不同回答。这不仅仅是语法的选择,更是“Pure JS”与“Enhanced HTML”两种技术信仰的对撞。
1.1 React 的设计哲学:Pure JS
React的核心信仰是,JavaScript 本身已经足够强大,不需要再发明一套新的语法来描述 UI。因此,React选择了 JSX —— 本质上是 JavaScript 的语法糖。
这种设计理念带来的最大优势是“图灵完备性”。在React组件中,你可以使用JavaScript拥有的一切能力:if-else控制流、switch语句、高阶函数的映射、甚至是递归。UI的构建逻辑与业务逻辑在语言层面上是完全统一的。
在React的编译阶段(通常由Babel处理),JSX会被直接编译为React.createElement函数调用。这意味着,对于React的编译器来说,它看到的只是一堆函数调用和变量。它很难知道这个变量是一个静态的字符串,还是一个会构建出巨大DOM树的组件。

这种“黑盒”特性导致React在编译阶段能做的优化非常有限。因为它无法确定运行时会发生什么,所以它必须假设一切都是动态的。
可以尝试编译上面的代码来一探究竟。
以下是React的编译结果:
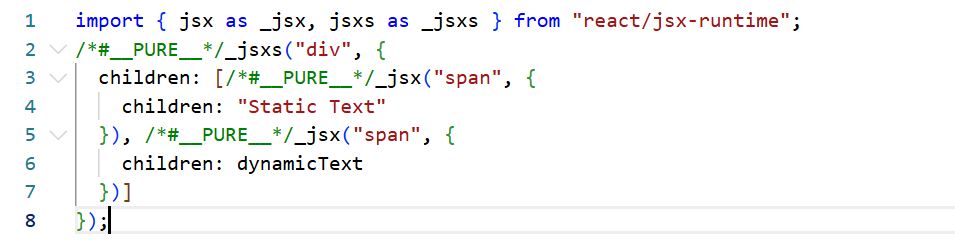
观察编译结果。我们会发现所有的元素都被编译成了_jsx调用,创建单个元素,没有任何标记区分静态和动态。React在运行时必须老老实实地比对这两个span,因为它不知道哪一个是静态的。
1.2 Vue 3 的设计哲学:Enhanced HTML
Vue选择了另一条路。尤雨溪团队认为,HTML 是描述 UI 结构最自然的方式。通过扩展 HTML(即 Template 模板),引入指令(v-if, v-for)等约束,可以构建一种“受限”的表达方式。
这种“受限”正是Vue性能优化的基石。因为开发者必须按照Vue规定的方式写代码(比如循环必须用v-for),这就给了编译器完整的视角去进行更深层次的优化。
Vue 3的编译器在解析模板时,会生成抽象语法树。由于语法的确定性,编译器可以精准地分析出哪些节点是永远不会变的(静态节点),哪些是会变的(动态节点),甚至知道它会怎么变(是文本变了,还是class变了)。这直接催生了Vue 3底层的核心优化技术:Block Tree(区块树)和Patch Flags(补丁标记)。
拿刚刚react同样的代码,看看vue3编译出来的结果:
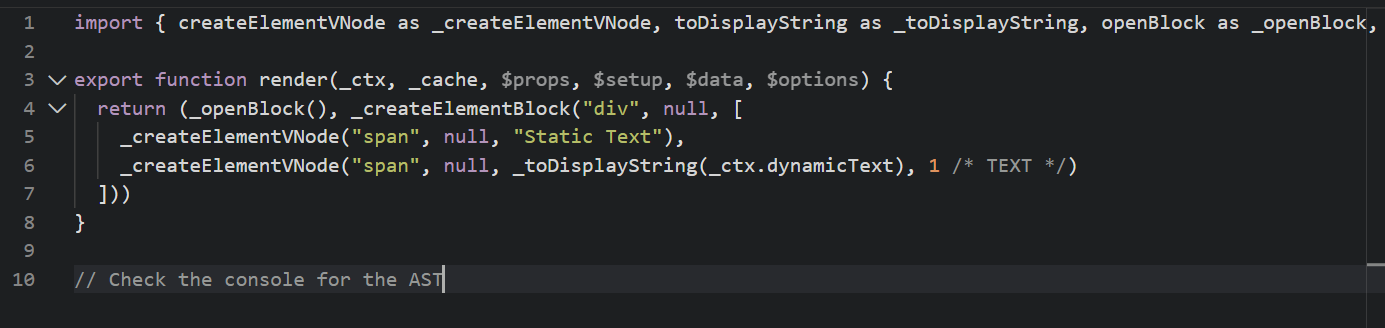
对比react的编译结果可以发现,vue3编译后明显区分了静态和动态数据,注意看第二个 _createElementVNode 函数的最后一个参数 —— 那个不起眼的数字 1(注释为 /* TEXT */,在 Vue 的源码中,1 代表 TEXT),这相当于给运行时下达了一道死命令:对于这个节点,你只需要检查它的文本内容(Text),其他所有属性(class、style)全是静态的。
总结来说,React选择了运行时的灵活性,代价是放弃了编译时的深度优化,必须依靠强大的运行时调度(Fiber)来兜底。Vue选择了编译时的确定性,通过牺牲一部分JS的灵活性(换成指令),换取了运行时极致的更新效率。
2. 响应式系统:推与拉的博弈
当状态发生变化时,框架如何感知并驱动视图更新,是框架的心脏。React和Vue在这里选择了截然不同的物理模型:Pull-based(拉取式)与Push-based(推送式)。
2.1 React 的设计哲学:不可变性与代数效应
React的理念是 UI = f(state)。它并不关心具体是哪个变量变了,它只关心“信号”。当调用 setState 时,React收到的信号是:“组件树的状态脏了,需要重新评估”。
这种设计极度简化了状态管理的心理模型:不需要监听数据,每次都重新渲染,只要保证渲染函数是纯函数即可。
由于React不知道具体哪个变量变了,为了计算出UI差异,它必须从组件树的根节点(或触发更新的组件)开始,递归地执行组件函数,生成新的虚拟DOM树,然后与旧树进行全量比对(Diff)。
这种机制的问题在于计算量。随着应用规模扩大,全量比对的成本呈指数级上升。这也是为什么React必须引入Fiber架构的原因——既然无法减少计算量(因为不知道谁变了),那就通过“时间切片”把计算过程切碎,不要阻塞主线程。
2.2 Vue 3 的设计哲学:细粒度响应与可变性
Vue 的理念是“精确打击”。它基于 ES6 Proxy 重构了响应式系统,建立了一张精密的依赖关系图。
Vue认为,框架应该知道确切的变化点。当一个数据变了,它应该直接通知依赖这个数据的组件(Effect)进行更新,而不需要去猜测。
Vue 3在底层利用Proxy拦截对象的get和set操作。当组件渲染时,读取数据触发get,Vue将当前组件的副作用函数(Effect)收集到该数据的依赖集合(Dep Set)中。当数据修改时,触发set,Vue从依赖集合中取出对应的Effect并执行。
这种机制的优势是更新粒度极细。无论应用多大,Vue都知道只需要更新哪几个组件。但代价是内存开销:每一个响应式对象和属性都需要维护依赖关系,这是一种“空间换时间”的策略。
响应式数据和副作用是函数的关系可以用下图概括: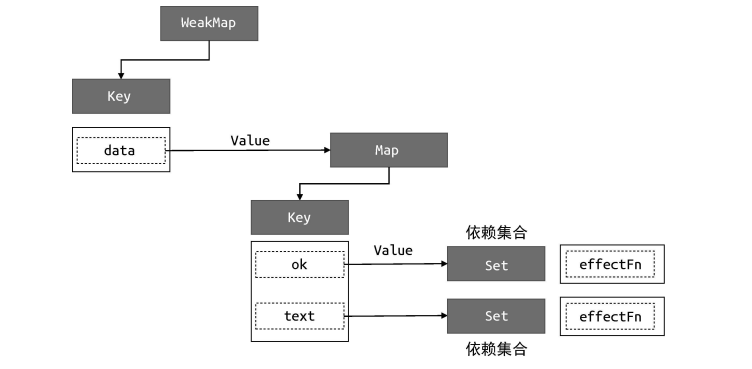
本质上讲,React是CPU密集型的思路:不管变了多少,重算一遍,但算得很有技巧(Fiber);而Vue是内存/逻辑密集型的思路:记录下所有的依赖关系,变了就直达病灶,绝不浪费一次计算。
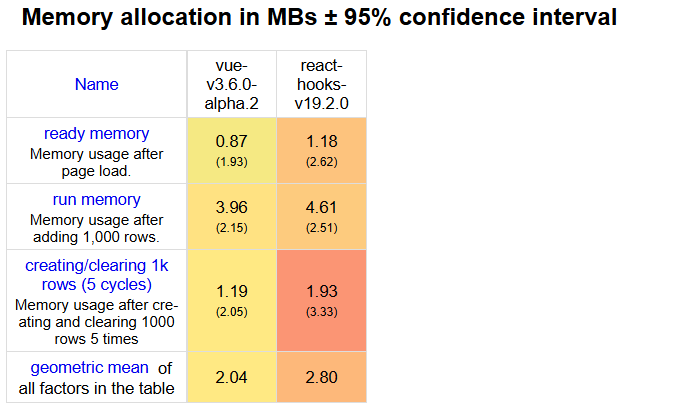
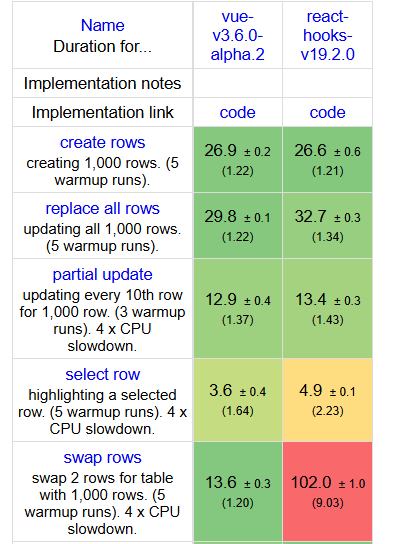 上面是一些常用的benchmark指标,来测试前端框架的一些性能。
上面是一些常用的benchmark指标,来测试前端框架的一些性能。
看“部分更新 (Partial Update)”部分和”swap rows” (交换两行)部分,Vue 3 明显较快而react明显较慢,这验证了 Vue 的 “Push-based” 细粒度更新,它不需要像 React 那样遍历子树,而是直接定位到了那几个变动的节点。
看 “ready memory” 或和”run memory”。
按照传统理论,我们往往认为 Vue 因为需要维护“依赖关系图(Dep Set)”和闭包,内存占用应该高于 React。然而我们看到了令人惊讶的结果:Vue 3 的内存占用竟然低于 React。
这正是 Vue 3 “编译时优化” 对抗 React “运行时开销” 的胜利。
在列表渲染中,Vue 通过静态提升,让大量静态标签在内存中只有一份引用。而 React 的 Fiber 架构虽然灵活,但它必须为每一个节点(无论静态动态)创建 Fiber 对象。
React 为了实现时间切片和优先级调度,其 Fiber 节点结构变得越来越复杂(包含大量指针和状态)。这意味着 React 是用内存空间换取了 CPU 的调度能力。
刚刚我们说“Vue 空间换时间”,现在看来,React 为了通过 Fiber 榨干 CPU 性能,在空间上的代价甚至已经超过了 Vue 的响应式系统。Vue 3 凭借极致的编译器优化,实现了双赢。
3. 运行时调度:Fiber 时间切片 vs 静态分析
这一部分是前两部分的必然结果。React因为不知道谁变了,所以必须在运行时做复杂的调度;Vue因为编译时就知道谁会变,所以在运行时可以走捷径。
3.1 React 的设计哲学:并发与调度(Concurrent Mode)
既然 React 选择了全量 Diff 的道路,它就必须解决“长任务阻塞主线程”的问题。React 团队受到操作系统“多任务处理”的启发,引入了 Fiber 架构。
Fiber的核心理念是:渲染过程是可以中断的。
React在底层将虚拟DOM节点重构为Fiber节点(链表结构)。它利用MessageChannel(在浏览器环境中)实现了类似于requestIdleCallback的机制。
在每一帧的时间窗口内(比如5ms),React执行一部分Diff任务。如果时间到了,任务还没做完,React就暂停,把控制权交还给浏览器去响应用户的点击或动画,等浏览器空闲了再回来继续做。
这就是React 18并发模式(Concurrent Features)的基础。它允许React在后台“悄悄”渲染,或者根据优先级打断当前的渲染任务。
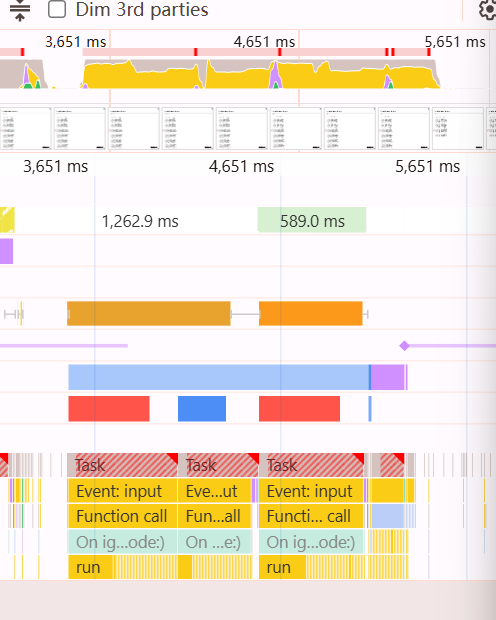 我们构建一个测试,构建一个包含5000个节点的长列表,然后进行即时过滤输入。
我们构建一个测试,构建一个包含5000个节点的长列表,然后进行即时过滤输入。
请观察上图的 Event: input 区域。
我们看到的不是一个阻塞主线程数秒的巨大色块,而是一系列被切分开的 Task(黄色方块)。注意看,在繁重的列表过滤计算过程中,浏览器依然能够插入新的 Event: input。这证明 React 的 Fiber 架构成功地中断了低优先级的列表渲染任务,优先处理了用户的键盘输入,从而保证了输入框的流畅度。
3.2 Vue 3 的设计哲学:编译器指导的虚拟 DOM
Vue 3 认为,如果能在编译阶段就把“静态的”和“动态的”分清楚,那在运行时就不需要像 React 那样做繁重的 Diff 工作,自然也就不太需要复杂的时间切片调度。结合第一部分提到的Block Tree。Vue的运行时Diff算法并不是传统的树形层级遍历,而是基于“动态节点列表”的扁平化遍历。比如有1000个节点,但编译器生成的结果显示只有3个节点是动态的,那就可以直接根据Patch Flag更新这3个节点,剩下的997个静态节点连看都不看。
这种技术被称为“编译器指导的虚拟DOM”(Compiler-informed Virtual DOM)。它将Diff的复杂度从与模板大小相关(O(n))降低到了与动态节点数量相关(O(dynamic))。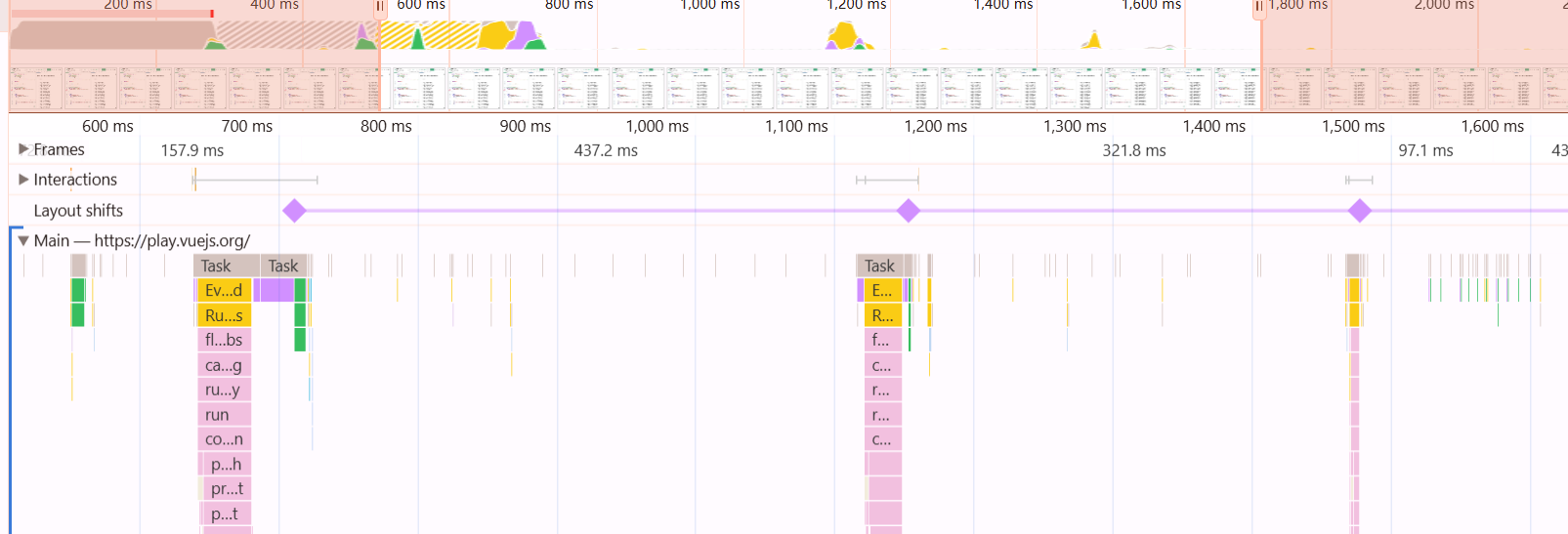
对vue3,进行如react一样的测试,5000个节点的长列表同时进行过滤输入。
结果如上图,每一次输入事件(图中黄色的小块)发生后,紧接着就是一根垂直向下延伸的调用栈(粉色/紫色)。
这是典型的 Run-to-completion(运行至完成) 模式:Vue 侦测到数据变化 -> 触发 Effect -> 重新计算 Computed -> Patch DOM。
在这个过程中,没有像 React 那样出现“缝隙”或“切片”。Vue一旦开始工作,就一口气干完,直到完成。
综合来看,React通过极度复杂的运行时架构(Fiber)解决了CPU瓶颈,这让它在处理超大规模、逻辑极度复杂的应用时表现出极高的上限。
Vue通过极度聪明的编译器优化,规避了CPU瓶颈,这让它在中小型甚至大型应用中,默认性能表现往往更好,且不需要开发者操心优化的事。
4. 逻辑复用:Hooks 的链表 vs Composition API 的引用闭包
最后,我们来看看经常接触的组件逻辑复用层面。
React Hooks的设计哲学:代数效应的模拟
React Hooks的设计初衷是解决Class组件逻辑复用难的问题。它试图在函数式组件中保存状态。React Hooks的底层实现极度依赖“调用顺序”。
在React的Fiber节点上,有一个memoizedState属性,它是一个链表。
当你第一次调用useState,React在链表上创建一个节点存值。
当你第二次调用useState,React在链表上下移一步创建第二个节点。
当组件重新渲染时,React再次按顺序遍历这个链表,读取对应的值。
这也是为什么React严格限制Hooks不能写在条件语句或循环中:一旦顺序乱了,链表就对不上了。同时,这也带来了“闭包陷阱”的问题,开发者必须极其小心地管理useEffect的依赖数组。
Vue Composition API的设计哲学:原生JS的引用
Vue的Composition API(setup语法)在设计上更符合JavaScript的原生直觉。setup函数只在组件初始化时运行一次。
由于setup只运行一次,Vue不需要像React那样去担心“多次渲染中保持状态”。
在Vue中,ref和reactive创建的是真正的响应式对象引用。
const count = ref(0) 创建了一个闭包环境下的对象。无论你在哪里访问count.value,它始终指向同一个内存地址。因此,Vue的Composition API不需要像React那样的依赖数组(Dependencies Array),也不存在闭包陷阱。它可以随意地写在条件语句中,因为它不依赖调用顺序,只依赖对象引用。
React Hooks虽然带来了极大的组合能力,但心智负担较重,需要开发者深刻理解闭包和依赖与时间的关系。
Vue Composition API在提供同等组合能力的同时,更符合JS的直觉,减少了“为了迁就框架而写的代码”。